
效能考量#
目前,Flax nnx.jit 在純 Python 中遍歷物件圖,這很慢且會增加開銷。這就是為什麼為了解決這個問題,Flax 團隊將開發一個名為 flaxlib 的 Rust 擴充功能,以加速 graph.py 中的一些遍歷邏輯。這將類似於 JAX 團隊透過引入 jaxlib 來解決標準 JAX pytrees 的類似問題(請參閱 Flax PR #4196 中的第一個步驟)。
然而,有兩件事需要考慮
開銷僅與小型模型相關(請參閱非同步調度)。
您可以使用
jax.jit+flax.nnx.split/flax.nnx.merge來移出遍歷邏輯,從而消除開銷(請參閱降低 Python 開銷)。
非同步調度#
在 benchmarks/nnx_simple_training.py 中,我們正在增加層寬(每層的特徵),並測量使用 nnx.jit 和 jax.jit 訓練的相同模型的總訓練時間。
如下圖所示,在達到一定的模型大小後,遍歷所花費的時間會被非同步調度完全吸收。當 Python 能夠完成目前的 for 迴圈步驟,並到達下一個 train_step,而 JAX 仍然沒有完成先前的 train_step 時,就會發生這種情況。
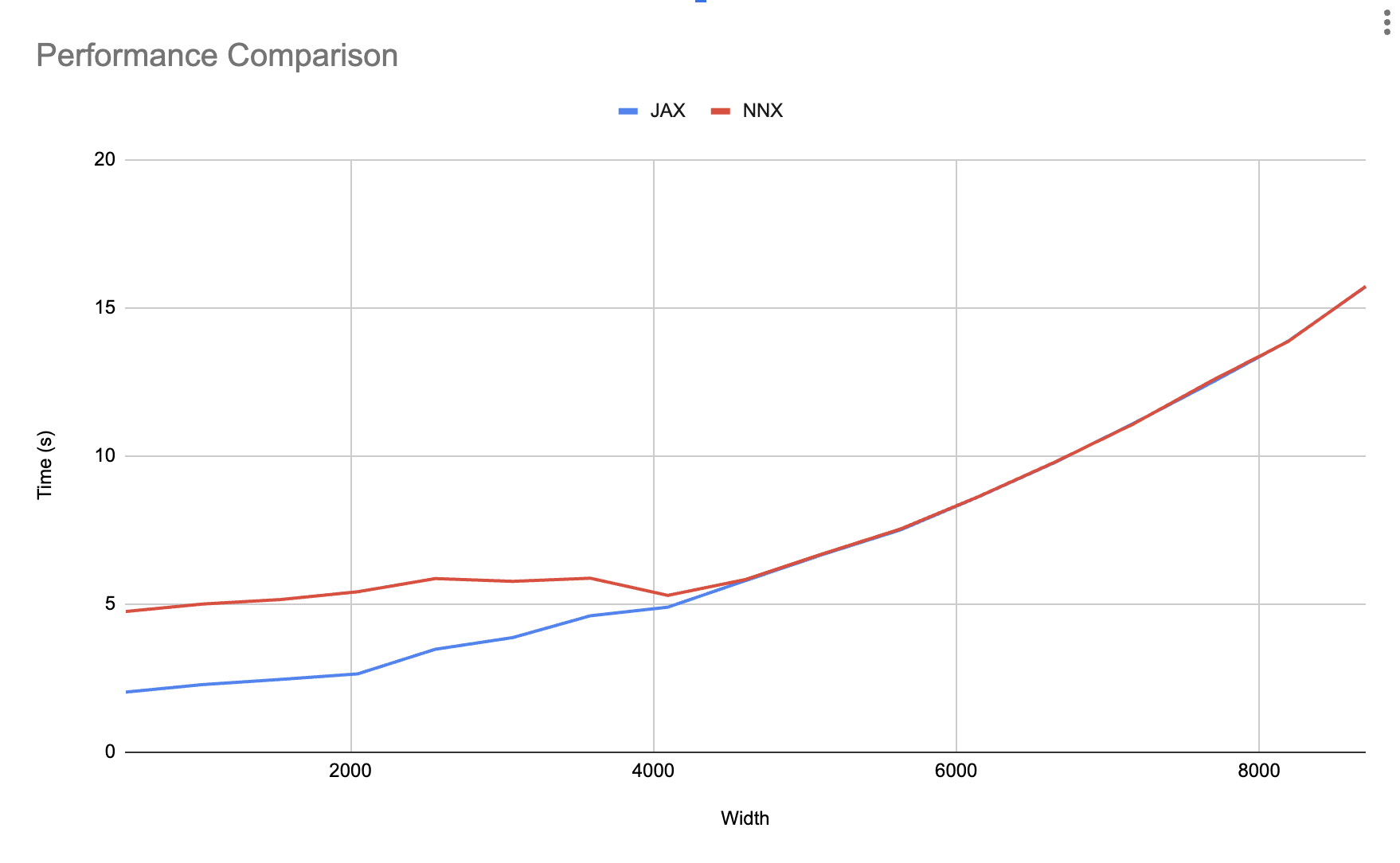
這意味著您只需要擔心小型模型的 nnx.jit 開銷。如果您正在使用小型模型,請查看下一節,了解如何消除開銷。
降低 Python 開銷#
要消除 Python 開銷,您可以結合使用常規的 jax.jit 與 nnx.split 和 nnx.merge 來移出遍歷邏輯。
為了了解如何做到這一點,讓我們先建立以下簡單的 Model
from flax import nnx
import jax
import jax.numpy as jnp
import optax
class Model(nnx.Module):
def __init__(self, din, dmid, dout, rngs: nnx.Rngs):
self.linear = nnx.Linear(din, dmid, rngs=rngs)
self.bn = nnx.BatchNorm(dmid, rngs=rngs)
self.dropout = nnx.Dropout(0.2, rngs=rngs)
self.linear_out = nnx.Linear(dmid, dout, rngs=rngs)
def __call__(self, x):
x = nnx.relu(self.dropout(self.bn(self.linear(x))))
return self.linear_out(x)
接下來,讓我們建立一個使用 nnx.jit 的 train_step() 函式,輸入 model、optimizer 和 metrics,它們都是 Flax NNX 物件
model = Model(2, 64, 3, rngs=nnx.Rngs(0)) # eager initialization
optimizer = nnx.Optimizer(model, optax.adam(1e-3)) # reference sharing
metrics = nnx.MultiMetric(
loss=nnx.metrics.Average('loss'),
)
@nnx.jit # <== currently slow
def train_step(model, optimizer, metrics, x, y):
def loss_fn(model):
y_pred = model(x) # call methods directly
return ((y_pred - y) ** 2).mean()
loss, grads = nnx.value_and_grad(loss_fn)(model)
optimizer.update(grads) # in-place updates
metrics.update(loss=loss)
return loss
for _ in range(10):
x, y = jnp.ones((32, 2)), jnp.zeros((32, 3))
loss = train_step(model, optimizer, metrics, x, y)
為了加快速度,在開始訓練迴圈之前,我們可以對 train_step() 的所有輸入 Flax NNX 物件使用 nnx.split 來建立 graphdef 和 state pytrees,這些 pytrees 的遍歷速度更快。
接下來,我們變更 train_step() 以接受 graphdef 和 state,並在 train_step() 的開頭和結尾使用 nnx.merge 和 nnx.split 來在物件及其 pytree 表示形式之間來回切換。儘管 nnx.split 和 nnx.merge 很慢,但這並不重要,因為它們只會在追蹤期間執行一次。
完成此設定後,我們可以將 train_step() 函式變更為使用 jax.jit 而不是 nnx.jit
model = Model(2, 64, 3, rngs=nnx.Rngs(0)) # eager initialization
optimizer = nnx.Optimizer(model, optax.adamw(1e-3)) # reference sharing
metrics = nnx.MultiMetric(
loss=nnx.metrics.Average('loss'),
)
# split before training loop
graphdef, state = nnx.split((model, optimizer, metrics))
@jax.jit # regular JAX
def train_step(graphdef, state, x, y):
# merge at the beginning of the function
model, optimizer, metrics = nnx.merge(graphdef, state)
def loss_fn(model):
y_pred = model(x) # call methods directly
return ((y_pred - y) ** 2).mean()
loss, grads = nnx.value_and_grad(loss_fn)(model)
optimizer.update(grads)
metrics.update(loss=loss)
# split at the end of the function
_, state = nnx.split((model, optimizer, metrics))
# return new state
return state, loss
for _ in range(10):
x, y = jnp.ones((32, 2)), jnp.zeros((32, 3))
state, loss = train_step(graphdef, state, x, y)
# update objects after training
nnx.update((model, optimizer, metrics), state)
請注意,我們只對 jit 執行此操作。您仍然可以使用其他 Flax 轉換,例如上述範例中顯示的 nnx.value_and_grad,因為它們的開銷已經被外部的 jit 吸收了。
在訓練迴圈完成後(或在需要時),我們可以使用 Flax nnx.update 將 Flax NNX 物件(例如 model、optimizer 和 metrics)更新為新的 state。